
A Convolution Based Speech Recognition Implementation
Note: The purpose of this post is as a personal reflection and not as a tutorial.
Relevant Links
Wav2Letter on Facebook Research
Paper: Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
Paper: Letter-Based Speech Recognition with Gated ConvNets
Paper: Language Modeling with Gated Convolutional Networks
GitHub PyTorch Implementation
- https://github.com/facebookresearch/wav2letter/tree/master/recipes/conv_glu
- Gated ConvNet Network Architecture: https://github.com/facebookresearch/wav2letter/blob/master/recipes/conv_glu/librispeech/network.arch
Gated Convolution
This paper: Language Modeling with Gated Convolutional Networks
has information on implementing gated convolutions used gated linear units. They present this equation: \(hl(X) = (X*W + b) \otimes \sigma(X*V + c)\)
I believe that the desired results for a gated convolutional layer can be achieved in TensorFlow with this code. I also added batch normalisation because in my experiments the outputs could sometimes explode to high values otherwise.
class GatedConvolution(tf.keras.layers.Layer):
def __init__(self, filters, kernel_size, dropout_rate, padding='causal'):
super(GatedConvolution, self).__init__()
self.convolution = tf.keras.layers.Conv1D(
filters=filters, kernel_size=kernel_size, padding=padding,
)
self.gated = tf.keras.layers.Conv1D(
filters=filters, kernel_size=kernel_size, padding=padding,
)
self.multiply = tf.keras.layers.Multiply()
self.norm = tf.keras.layers.BatchNormalization()
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, training):
convolution_output = self.convolution(x) # (batch_size, input_seq_len, d_model)
gate_output = tf.keras.activations.sigmoid(self.gated(x))
output = self.multiply([convolution_output, gate_output])
output = self.norm(output, training=training)
output = self.dropout(output, training=training)
return output
Network Structure
The facebook research paper presents 3 different network architectures. I’ll start by implementing the one that was designed for the WSJ dataset. Note that the PyTorch implementations are available on their GitHub and it was there I found this architecture file:
WN 3 C NFEAT 200 13 1 -1
GLU 2
DO 0.25
WN 3 C 100 200 3 1 -1
GLU 2
DO 0.25
WN 3 C 100 200 4 1 -1
GLU 2
DO 0.25
WN 3 C 100 250 5 1 -1
GLU 2
DO 0.25
WN 3 C 125 250 6 1 -1
GLU 2
DO 0.25
WN 3 C 125 300 7 1 -1
GLU 2
DO 0.25
WN 3 C 150 350 8 1 -1
GLU 2
DO 0.25
WN 3 C 175 400 9 1 -1
GLU 2
DO 0.25
WN 3 C 200 450 10 1 -1
GLU 2
DO 0.25
WN 3 C 225 500 11 1 -1
GLU 2
DO 0.25
WN 3 C 250 500 12 1 -1
GLU 2
DO 0.25
WN 3 C 250 500 13 1 -1
GLU 2
DO 0.25
WN 3 C 250 600 14 1 -1
GLU 2
DO 0.25
WN 3 C 300 600 15 1 -1
GLU 2
DO 0.25
WN 3 C 300 750 21 1 -1
GLU 2
DO 0.25
RO 2 0 3 1
WN 0 L 375 1000
GLU 0
DO 0.25
WN 0 L 500 NLABEL
It is difficult to work out exactly what this is communicating but I believe that (WN 3 C) represent convolutions, (WN 0 L) represents linear layers, (GLU 2) represents gated linear units and (DO) represents dropout.
The corresponding paper: Letter-Based Speech Recognition with Gated ConvNets
also gives hints as to what the parameters are corresponding to.
From this information I designed this TensorFlow model:
class GatedConvolutionalEncoder(tf.keras.Model):
def __init__(self):
super(GatedConvolutionalEncoder, self).__init__()
self.num_convolutions = 14
self.convolutions = [GatedConvolution(filters=100, kernel_size=3, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=100, kernel_size=4, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=100, kernel_size=5, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=125, kernel_size=6, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=125, kernel_size=7, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=150, kernel_size=8, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=175, kernel_size=9, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=200, kernel_size=10, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=225, kernel_size=11, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=250, kernel_size=12, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=250, kernel_size=13, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=250, kernel_size=14, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=300, kernel_size=15, padding='causal', dropout_rate=0.25),
GatedConvolution(filters=300, kernel_size=21, padding='causal', dropout_rate=0.25)]
self.fc1 = tf.keras.layers.Dense(1000)
self.final_layer = tf.keras.layers.Dense(input_vocab_size)
def call(self, inp, training=True):
output = inp
for i in range(self.num_convolutions):
output = self.convolutions[i](output, training=training)
#output = self.convolutions[0]
#output = self.convolutions[1]
output = self.fc1(output)
output = self.final_layer(output)
return output
Training
I trained on the JVS Japanese dataset. I identified some very strange and unstable training curves.
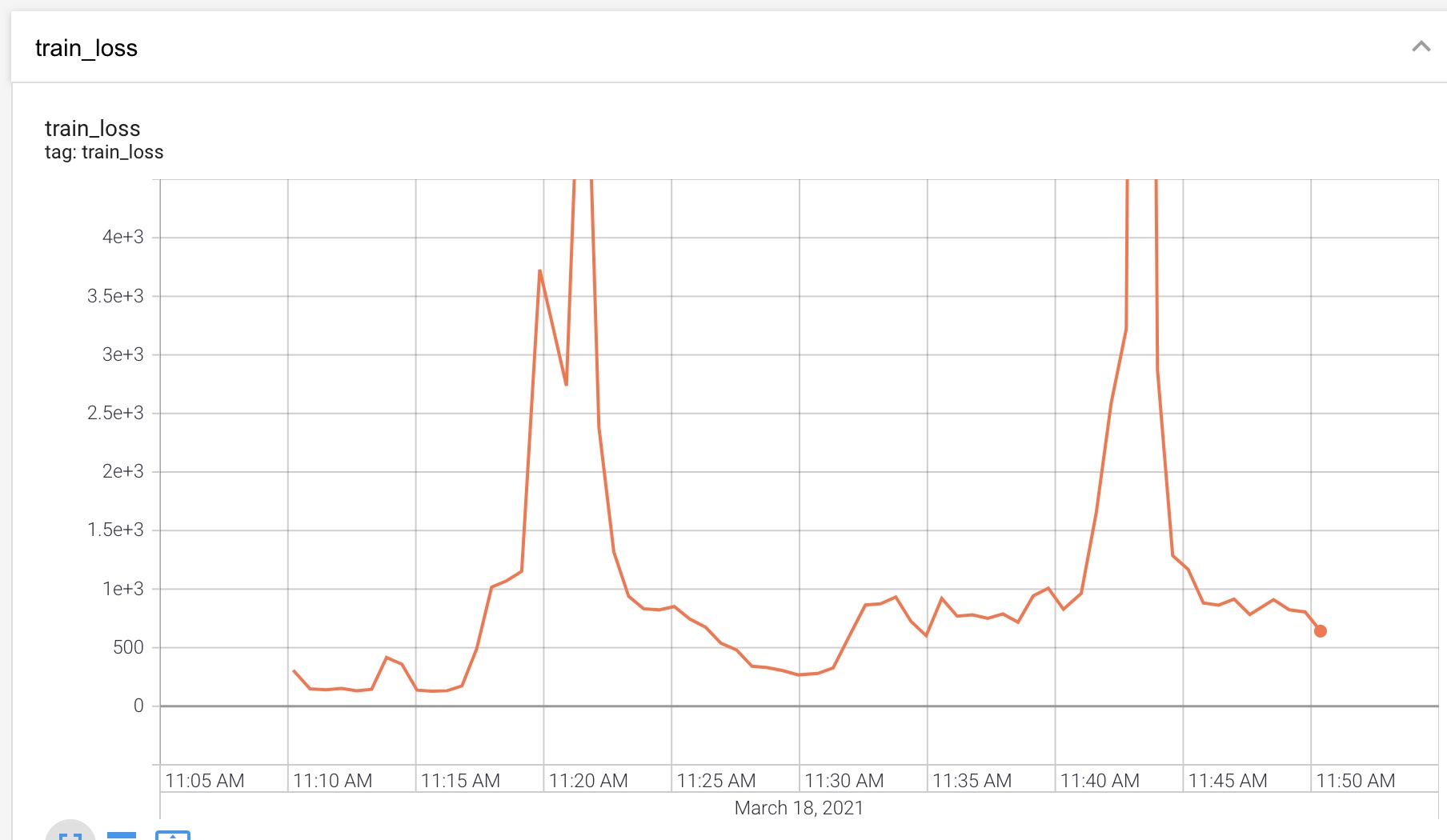
I thought that perhaps I had implemented the gating incorrectly so I experimented with removing this and just having convolutions but these large value explosions still occured.
I then tried changing datasets to the JSUT which is shorter and has a single speaker.
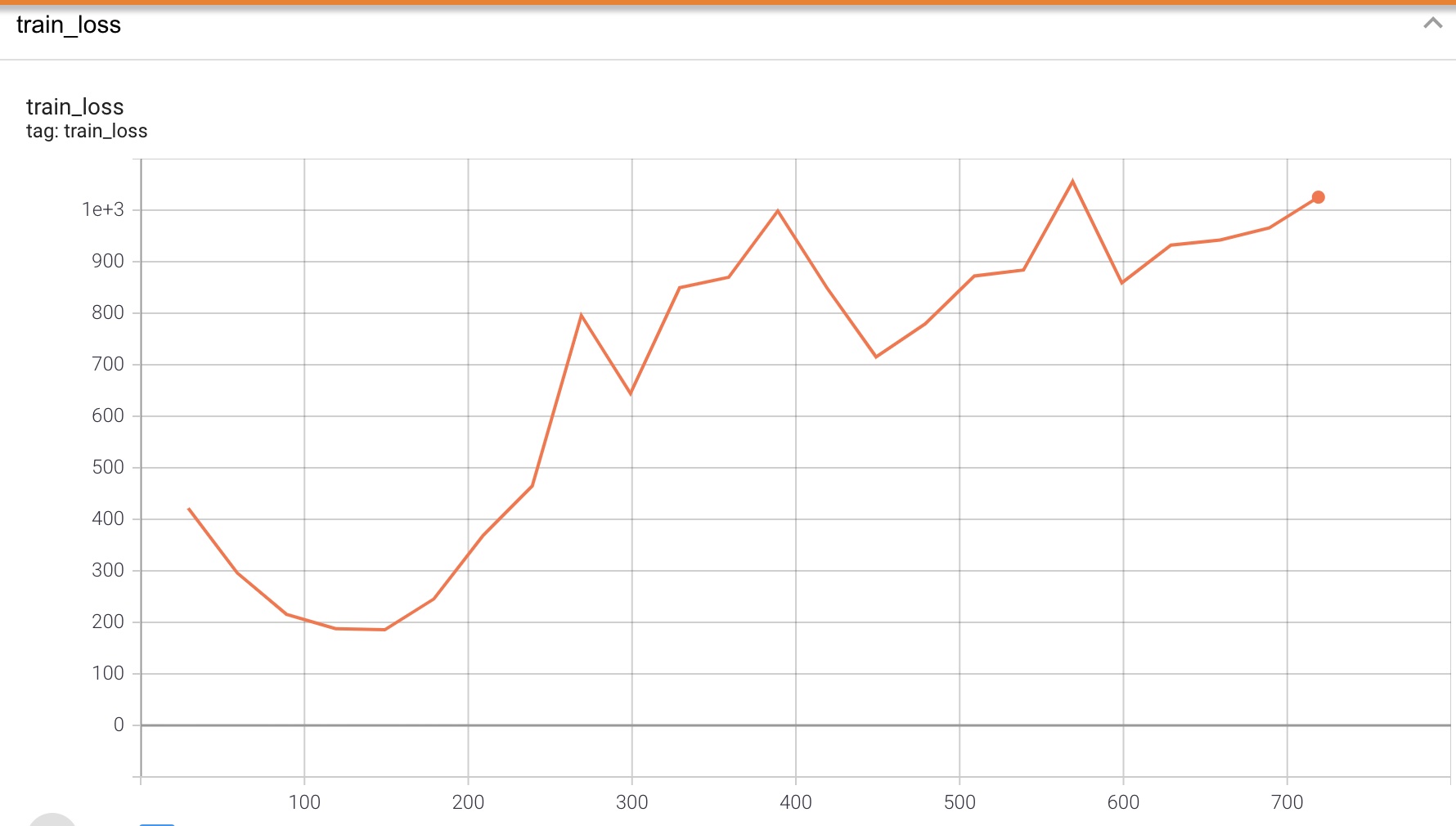
The training curve still exhibited strange behaviour where it would decrease and then increase. This is a normal pattern to see on a validation curve when there is overfitting but it seemed very strange that this would happen on a training curve.
I searched what might cause this and I found that people had similar strange increases in the training curve when they used Adam optimiser with a learning rate that was too high. I changed the learning rate from 0.001 the default to 0.00001. I then trained for 5 epochs on JSUT.
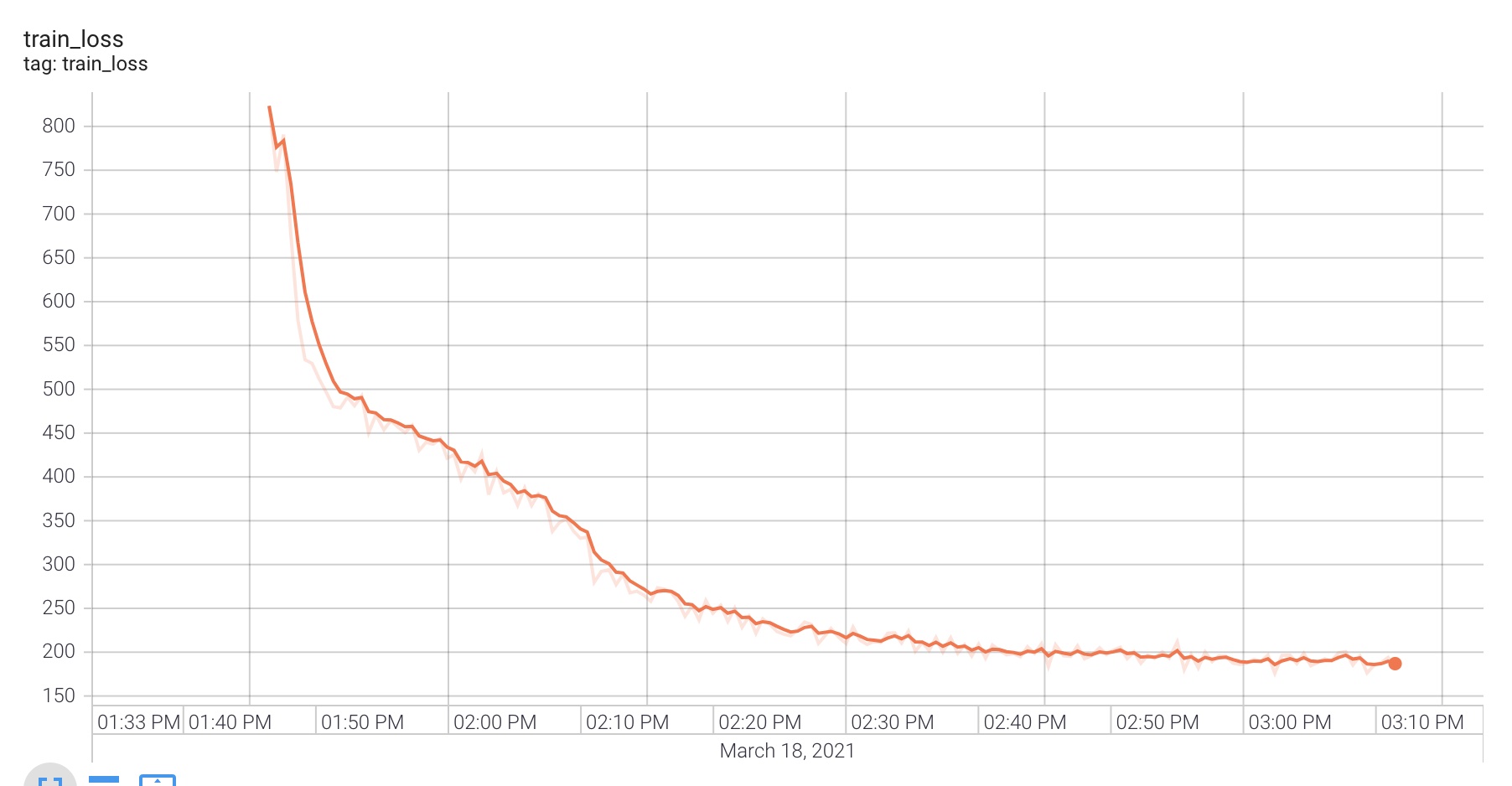
I now have a reasonable training curve shape, however I feel the loss is still too high and the model is failing at its task of speech recognition. I then try with the larger JVS dataset for 5 epochs.
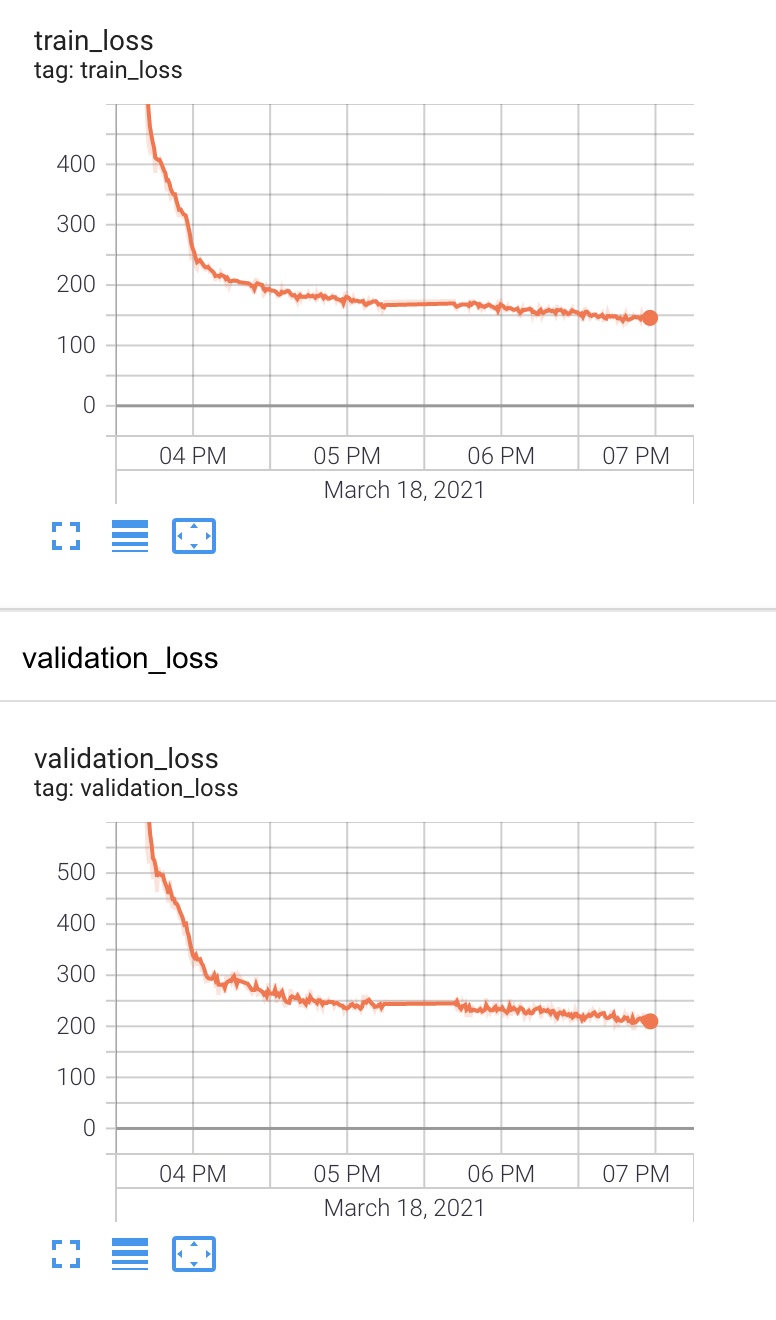
The training and validation loss still seems to be decreasing, so I will try training for a bit longer.